Gradient Descent
The purpose of the gradient descent is to minimize the function. The more mathematical term is called the method of least squares.
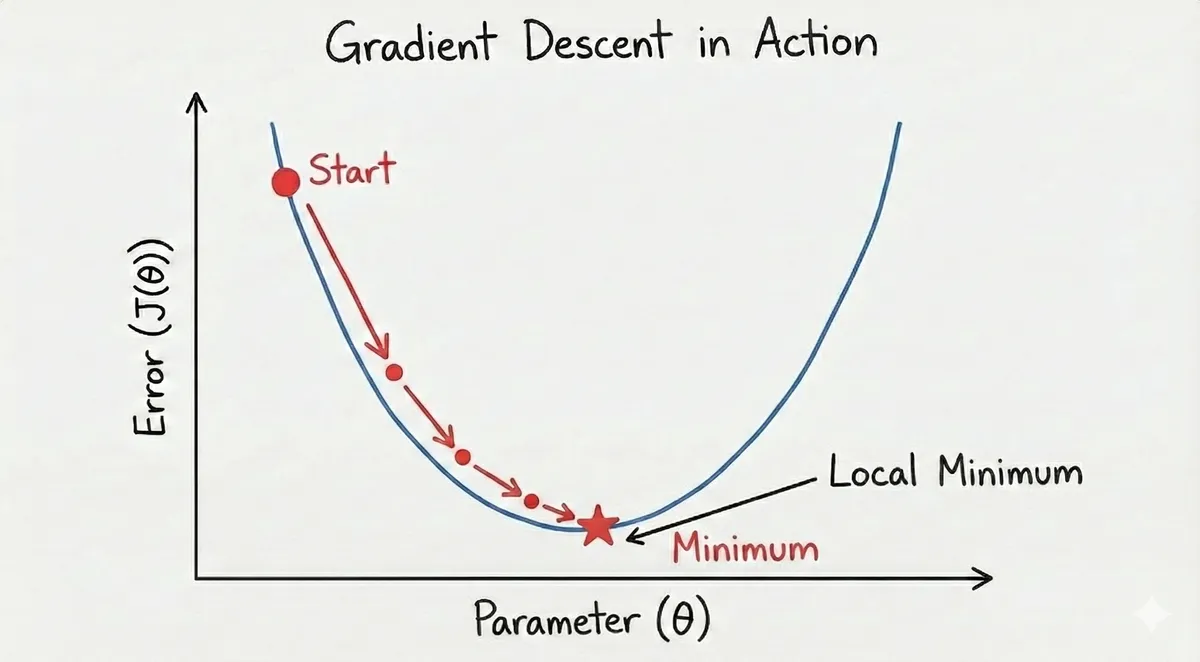
Why is the gradient descent specifically because the original formula for a line is but that does not have a bottom since a line is continuous and infinite, meaning there is no end. Whereas, the parabola is U-shaped which means there is a true bottom and that is the idea of what neural networks are based on, to minimize the error.
Gradient descent has few key components:
- Derivative, since then the derivative is
- Learning rate (alpha)
- The current guess
With the help of coding, we can introduce this in a simpler fashion without doing any crazy calculus work.
for x in range(tries):
derivative = 2 * x # This is the current position
current_guess = current_guess - alpha * d # This is updating to a new position, which should be closer to the minimum or minimizing the error
return current_guess # Show the new position
# Source: GPT Learning Hub
So, in simpler terms, when we run for a number of iterations, the derivative is being calculated and we can get new positions for each iteration, thereby, reaching the minimum which is zero. Now how does that work or why does it work that way?
Let's use an example, we can calculate:
Based on the example, we can see the new position is closer to 0 than the previous position (3), therefore, we move towards the left of the curve. Vice versa, if the new x value was negative, we would move towards the right of the curve.
So why does it matter?
All AI models use gradient descent, specifically neural networks. The key idea is to minimize the error, basically our new guess should be close to zero, however becoming zero itself is usually not possible but kept as a theoretical goal for model evaluation. When we have a model that is close the minimum (or towards the bottom of the descent) then we can say to a good degree our model can provide good predictions, however, other metrics also play a factor in overall model evaluation.
Now, when I mention error, it is different from the current or new position. Typically, the error is usually squared based on the new position (or guess). So in practical terms, we would get the error by truelabel - predictedlabel and then we square to get the error, therefore, error is always positive and never negative. This can be done using scikit-learn and/or PyTorch libraries.
A higher LR tends to lead to larger steps on the descent, however, there is a higher risk of overshooting the minimum. A lower LR will lead to more conservative steps but can take a longer time for the model to converge, therefore, more expensive training process.
So from my understanding, typically model training is done using PyTorch so optimizers and learning rates come into effect for the gradient descent part internally. The optimizer is telling the model which the best direction to move to go towards the bottom, it is usually used to optimize the cost function parameters which are weights and biases and the learning rate is set to analyze how large or small the step is towards the minimum. Highly fundamental concept in machine learning which I always keep in mind while training neural networks.