Linear Regression
Linear regression is a fundamental concept in machine learning. It is heavily used in all sorts of deep learning architectures such as neural networks as an example. As a matter of fact, even ChatGPT uses linear regression to an extent.
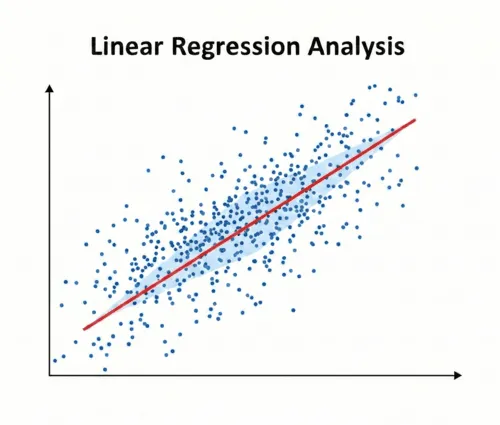
So why is linear regression called linear regression? The term regression basically means we have a line and we can an n number of predictions/outputs/probabilities as opposed to a classification which follows a set number of inputs and provides a set number of predictions. A classification example could be to identify which animal is in the image, a dog or a cat. A regression example could be prediction of an individual's body temperature.
We can take the example of someone's body temperature. Regression will provide a numerical output and the linear part takes in some number of factors/inputs and multiplies into weights plus a bias. So the end product is a prediction of an individual's temperature based on those factors.
The easy mathematical way would show as is:
This is a super simple an intuitive way of explaining linear regression. Another part is B (bias), this is a sort of base factor or value that the model usually comes up by the model itself and becomes a better value over the course of training.
So when we do a linear regression, we would have two variables; the dependent variable and the independent variable. So, when we get the prediction from a linear regression model, it would be values not originally present in the training set. The key is to find the best fit in the dataset, if there is no best fit around the data points, then the model will not provide any useful information.
Over a period of iterations, we get an error value, that error value typically goes down and hopefully becomes better over time. Now, the most common error function is called the mean squared error. The theoretical value of what the best error value would look like is 0. However, in practical terms we would not reach zero in model training.
The formula for MSE would be:
So we take the sum of some number of total samples, iterate and get the difference i.e. prediction and ground truth value divided by the total number of samples. Now, the question asked is, why do we square them? We square the value to avoid the negative and only get the average.
To conclude, linear regression is easy to set up in Python using scikit-learn library and quick to use on a lot of continuous data types. It provides accurate predictions with speed and efficiency.