Neural Networks
Before the Transformer boom, the neural networks was the new hype which was based on the human brain's neuron power and overall capability.
In this post, we will delve deep into neural networks at a theoretical level and build from scratch with the use of PyTorch so that we can understand each step and how it works during the full training process.
When we start explaining a NN, it begins with the perceptron which explains the structure of how stimuli plays an effect on the cells being activated of a network. It provides the approach of 'all-or-nothing', either stimuli is provided and a response is provided, otherwise no response is provided. This approach had a good foundation of how a neural network is structured and the proper training process. However, limitations were present, the weights followed a simple logical check instead of using an algorithm to optimise the weights, so therefore, the network could not solve more complex data types. The paper: Perceptron
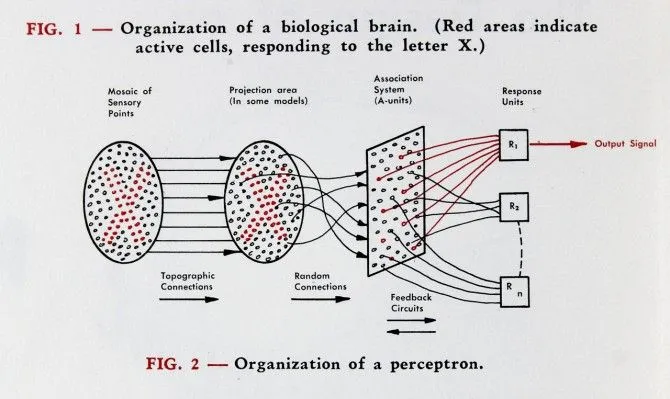
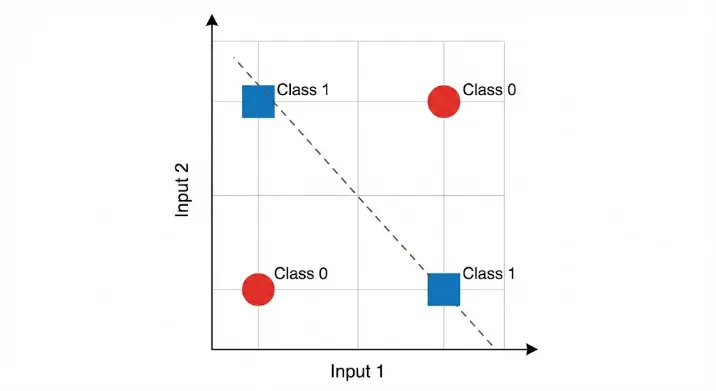
Another paper discussing the XOR problem came to fruition which means the perceptron cannot handle non-linearly separable functions as the gradient/slope is always 0, a linearly separable problem includes having a straight line to distinguish the classes but in cases it is difficult to separate these classes because of the arrangement. For example, if you have two classes 0 and 1 and plot points on a piece of paper as (0,0), (0,1), (1,0) and (1,1), no matter the straight line there will be no separation. Therefore, the introduction of the multi-layer perceptron and hidden layers solve the XOR problem.
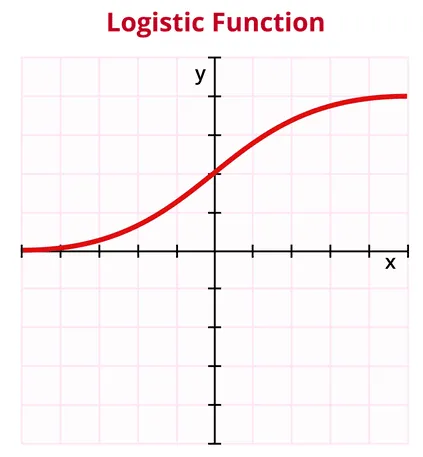
The paper by Geoffrey Hinton was the breakthrough research which heavily addresses the XOR problem. Additionally, the introduction of the sigmoid function which is 'S' shaped and allows for neural networks to learn non-linear cases and providing an output between 0 and 1 which is a prediction. The paper: LA for Boltzmann Machines
Now with that information we can code up a simple perceptron network from scratch with PyTorch. Keep in mind this example represents a linear example. An example to depict the training process for a simple perceptron, some concepts maybe foreign here but will be touched on in later posts.
import torch
import torch.nn as nn
import torch.optim as optim
# Perceptron with sigmoid activation
class Perceptron(nn.Module):
def __init__(self, n_features):
super().__init__()
# Performs linear regression wx + b
self.linear = nn.Linear(n_features, 1)
# Output transformered between 0 and 1
self.sigmoid = nn.Sigmoid()
# Forward pass
def forward(self, x):
z = self.linear(x)
return self.sigmoid(z)
# Linearly separable example
# Single feature input
X = torch.tensor([[0.],
[1.],
[2.],
[3.]])
# Binary labels, ground truth
y = torch.tensor([[0.],
[0.],
[1.],
[1.]])
model = Perceptron(n_features=1)
# Loss function
criterion = nn.MSELoss()
# Optimizer function stochastic gradient descent
optimizer = optim.SGD(model.parameters(), lr=0.5)
# Training loop
for epoch in range(1000):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward() # backpropagation
optimizer.step() # update weights
# Evaluation
with torch.no_grad():
probs = model(X)
preds = (probs > 0.5).int()
print("Probabilities:")
print(probs)
print("Predictions:")
print(preds)
Overall, neural network shows a lot of promise for various tasks especially in computer vision cases. PyTorch provides a huge plethora of ready-made library functions to help create neural networks. Having an understanding of the basics can definitely help us visualise how neural networks work from the beginning all the way to the training process and therefore, help us code the program.